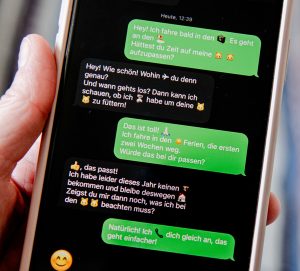
Mit dem Textometer bietet IMKIS schon seit einiger Zeit ein Tool, das die Verständlichkeit von Texten bewertet. Neu ist, dass der Textometer jetzt auch lange Wörter und lange Sätze einfärbt. Probieren Sie es mal mit eigenen Texten aus!
Von Hannah Molderings

Was ist der Textometer und wofür wird er genutzt?
Der Textometer ist ein kostenloses Tool von IMKIS, mit dem Sie die Verständlichkeit von Texten schnell bewerten können.
Wie funktioniert der Textometer?
Sie fügen Ihren Text in das Tool ein und erhalten sofort eine Bewertung der Verständlichkeit. Grundlage ist eine spezielle Formel (BLIX), die unter anderem Satzlänge und Wortlänge berücksichtigt. Pressetexte zum Beispiel sollten einen BLIX-Wert von unter 20 haben, Texte fürs bloße Hören (Statements, Reden etc.) müssen einen noch niedrigeren Wert aufweisen.
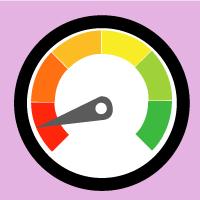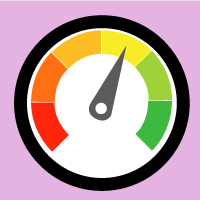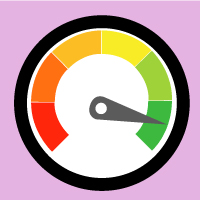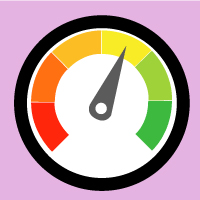
Welche Ergebnisse zeigt der Textometer an?
Sie erhalten drei einfache Rückmeldungen:
• einen Kennwert (BLIX)
• eine Einschätzung in Schuljahren
• eine Bewertung der Textverständlichkeit von „sehr einfach“ bis „sehr schwierig“
Was ist neu am Textometer?
Der Textometer markiert jetzt automatisch lange Sätze und lange Wörter. So erkennen Sie auf einen Blick, wo Ihr Text schwer verständlich ist.
Was bringen mir die Markierungen für lange Sätze und Wörter?
Sie helfen Ihnen, problematische Stellen gezielt zu überarbeiten.
Warum sind die Messwerte aussagekräftig?
Die Forschung zeigt: Ein einfacher Stil hängt stark mit guter Verständlichkeit zusammen. Also: kürzere Sätze, verständliche Wörter, weniger Substantive. Blindstudien kommen dabei zu ähnlichen Ergebnissen wie solche Messverfahren.
Ist die Nutzung des Textometers sicher?
Ja. Ihre Texte werden nur im Browser verarbeitet und nicht gespeichert oder weitergegeben. Sie können den Textometer sogar herunterladen und ganz ohne Internetverbindung lokal benutzen.
Wie zuverlässig sind die Ergebnisse?
Die Werte sind umso verlässlicher, je länger der Text ist. Bei extrem kurzen Texten machen Kleinigkeiten eben viel aus.
Ersetzt der Textometer das Gegenlesen von Texten?
Nein. Das Tool bewertet vor allem Stilmerkmale wie Satz- und Wortlänge. Für Inhalt, Logik und Zielgruppenansprache bleibt menschliches Feedback wichtig.
Wer hat den Textometer gebaut und für wen ist er da?
Der Textometer ist eine Gemeinschaftsentwicklung der beiden Germanisten Katrin Liffers und Stefan Brunn mit der Kognitionswissenschaftlerin Hannah Molderings und dem Datenjournalisten Sebastian Mondial.
Wo findet man den Textometer?
www.textometer.de

Neugierig geworden?
Wir von IMKIS lieben es, Entwicklungen rund um Kommunikation und Sprache zu durchleuchten – und geben dieses Wissen auch in Seminaren weiter. Vielleicht finden auch Sie etwas in unserem Portfolio?
UNSERE SEMINARE


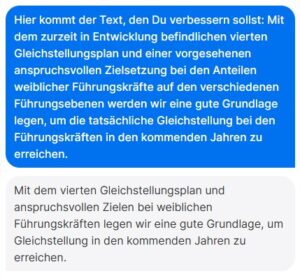
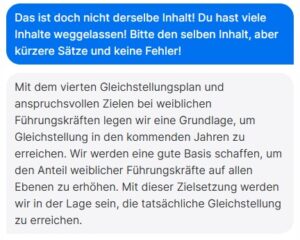



 Wenn amerikanische Manager:innen sich von ihrem Stab für Entscheidungen informieren lassen, geschieht das oft nach dem gleichen Schema. Dahinter steht ein einfaches, aber sehr intelligentes Reflexions-Modell. Wir erklären, woher es stammt und wie es funktioniert.
Wenn amerikanische Manager:innen sich von ihrem Stab für Entscheidungen informieren lassen, geschieht das oft nach dem gleichen Schema. Dahinter steht ein einfaches, aber sehr intelligentes Reflexions-Modell. Wir erklären, woher es stammt und wie es funktioniert.